Influx Database Writer Service
| This page refers to a remote repo, and is only temporarily included here. |
Overview
The Influx DB Writer service is a JavaScript programme running in a NodeJS container that receives messages from the EP Mediation Device via an MQTT Broker. These messages are then structured to form the buffers for the Influx Time Series database and written to the appropriate bucket for subsequent presentation via Grafana. If that all makes sense then skip to the section on Code Structure. If a little more context and explanation is required stick with us over the next few sections.
Components
Influx DB
The Influx DB database is an open-source time series database available under the MIT open source license or as a SaaS cloud offering. A commercially supported “hardened” version is available as an “enterprise” offering. The database is a time-series database that is optimised for storage and retrieval of data points in their associated time order. The database is written in Google’s open-source Go programming language.
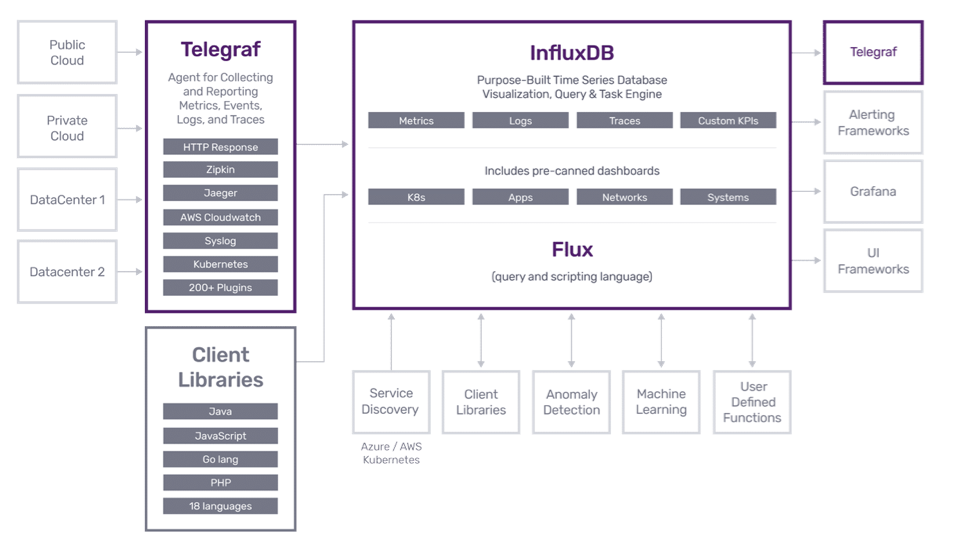
Influx has gathered around it a number of other open-source implementations to create a little ecosystem - often referred to as the TICK stack from the initial letters of those components:-
-
Telegraf an agent component for collecting and reporting metrics;
-
InfluxDB itself;
-
Cronograf a user interface to drive the platform and create reports;
-
Kapacitor a data-processing engine for batch data from the InfluxDB The influx-dbwriter does not use these components but a future study might look at replacing it with Telegraf which has plugins that support MQTT
MQTT Broker
Central to the communication between the mediation devices that monitor and control the elements of the microgrid (the EP Platform) and the cloud-based components that configure and report upon them are a series of MQTT Brokers. The brokers provide a link for JSON payloads with a well defined Quality of Service metric.
MQTT is a Client Server publish/subscribe messaging transport protocol. It is a light weight, open, simple, and designed so as to be easy to implement. The features were influenced by the features of IBM MQ Series but the protocols and service are original. These characteristics make it ideal for use in many situations, including constrained environments such as for communication in Machine to Machine (M2M) and Internet of Things (IoT) contexts where a small code footprint is required and/or network bandwidth is at a premium.
The device instarces which form part of the EP platform publish their status and data ‘signals’ to the cloud as published messages against a series of predefined topics that the cloud components can monitor as subscriptions to those topics.
Influx-Writer
The inflix-writer is a custom JavaScript module that is designed to run inside a NodeJS container and implements a “micro service” that receives messages from the MQTT broker, formats them into batches and writes them to the InfluxDB database. To do this it uses the standard InfluvDB APIs. In particular the write to DB API is used to create time series data in one of the “buckets” associated with the InfluxDB instance. The API protocol populates data values from by the influx-writer service which must supply:
-
Measurement (required)
-
Tags: Strictly speaking, tags are optional but most series include tags to differentiate data sources and to make querying both easy and efficient. Both tag keys and tag values are strings.
-
Fields (required): Field keys are required and are always strings, and, by default, field values are floats.
-
Timestamp: Supplied at the end of the line in Unix time in nanoseconds since January 1, 1970 UTC - is optional. If you do not specify a timestamp, InfluxDB uses the server’s local nanosecond timestamp in Unix epoch. Time in InfluxDB is in UTC format by default.
The influx-writer is an event driven continuous service primarily run under a NodeJS instance that exposes no services other than an optional HealthCheck service but acts as a daemon reading published MQTT messages for specific topics and buffering them for write to the InfluxDB.
InfluxDB Versions
The influx DB is in the process of significant architectural change from versions 1.x to 2.x. Version 2.0 is currently at release candidate status and provides in a single binary multi-tenanted time series database, UI and dashboarding tools, background processing and monitoring agent, all behind a single API. It provides an entire TICK stack in one deployment with shareable dashboards, alerts and queries optimized for specific workloads and solutions.
Although elements of the Flux query language were available in InfluxDB version 1.x the newer release offers a language designed for data scripting, ETL, monitoring and alerting.
The influx-writer can support both versions of InfluxDB by configuring the INFLUX_DB_V2 environment variable to true.
Context Diagram
The context diagram illustrates the basic components that make up the Smarter Micro Grid
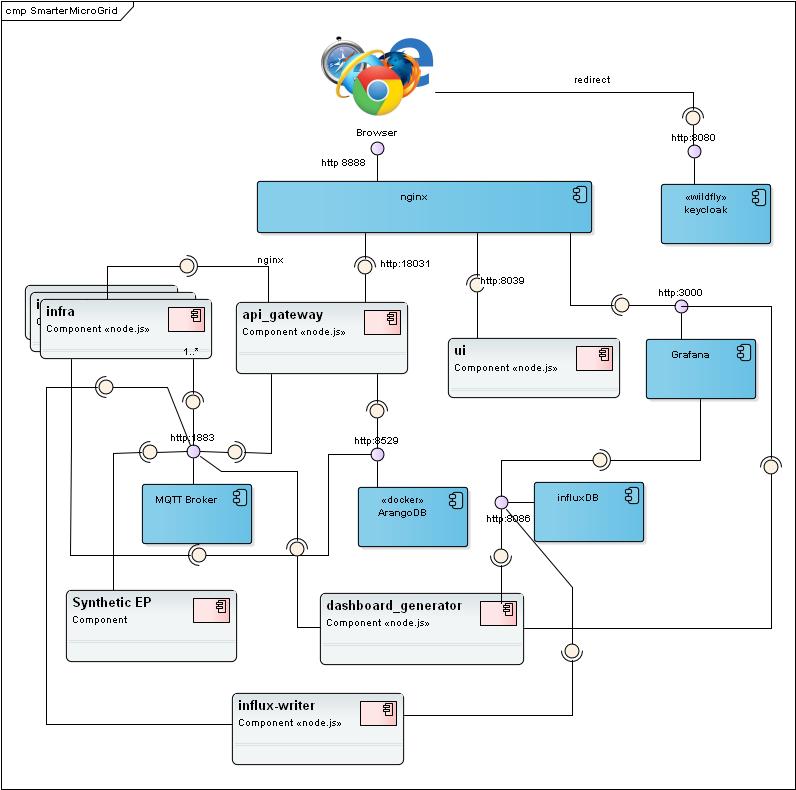
The context diagram above illustrates the key components of the SMC cloud infrastructure. Briefly these are:-
NGINX
A lightweight proxy that is used to supply a single endpoint to a users browser allowing content from multiple sources to be combined in a single UI screen. The nginx proxy routes browser requests to the correct downstream component based on pattern matches on the incoming URLs. By using nginx as a single access point, issues around Browser cross-origin-resource-sharing (https://en.wikipedia.org/wiki/Cross-origin_resource_sharing#:~:text=Cross%2Dorigin%20resource%20sharing%20(CORS,scripts%2C%20iframes%2C%20and%20videos.[CORS]) can be alleviated and UI implementation simplified
Keycloak
Keycloak, an open source Identity Access and Access Management solution that is used to manage users and control their access to the various infra components. Access tokens for elements such as the InfluxDB are managed and distributed to individual users from the Keycloak instance.
Infra APIs
One or more infra APIs are managed by a single gateway-api instance. The infra API components are custom built JavaScript NodeJS microservice collections. Each provides a series of REST services specific to a collection of EP devices within a given microgrid or namespace. In general there will be at least one infra component instance in each deployment but there may be multiple versions to model multiple grids or namespaces.
API Gateway
The API gateway-api is a concentrator for access to the various SMC data sets and services. Like the infra API, the gateway-api is another custom built JavaScript NodeJS microservice collection. It is intended to form the access point for data from the user interface that runs in the customer’s browser
Grafana
Grafana is a cloud and on-premises platform that supports analytics for gathered metrics, the creation and management of dashboards etc. SMC uses a private cloud instance hosted in AWS at https://ui.cloud.smartermicrogrid.com/grafana/
MQTT Broker
The MQTT Broker forms the common transport layer between the various elements of the software infrastructure. Whilst not directly related to IBM MQ Series, Message Queueing Telemetry Transport was originally designed by a couple of IBMers and borrows a lot of the concepts that will be familiar to users of WebSphere MQ and MQ Series. There are several excellent MQTT brokers with mosquito, Aedes and Hive being probably the most popular. The AWS instance of smartermicrogrid uses mosquitto from the Eclipse project.
Arango Database
Arango is a graph and document database that is used to hold data from devices and signals captured from the microgrid infrastructure as well as meta-data used by the SMC software. The Graph database is not used by the Influx-Writer.
Synthetic EP
The synthetic EP is only used during test and development. In these configurations it is simply a source of device and signal data. In production signals and device measurements are written form the EP mediation devices in the field onto the MQTT broker.
Dashboard Generator
The dashboard generator is an automated process that will use our existing components to create dashboards for the devices that have been registered in the ArangoDB database. It is another NodeJS process that uses a number of our infrastructure elements to write records into Grafana.
Influx Writer Technical Detail
Influx Writer Context
Source Code
The JavaScript code can be found in the BitBucket Repository at:-
git clone https://<YOUR_ID>@bitbucket.org/smc-dev/influx-writer.git
DGCSDEV Dependencies
The influx-writer has a dependency on the following other JavaScript modules which also form part of the SMC Codebase:-
-
@dgcsdev/edge-schemas version 21.4.1 or greater
-
@dgcsdev/edge-service-wrapper version14.10.3 or greater
These dependencies create indirect dependencies on the following other SMC modules
-
@dgcsdev/edge-mqtt
-
@dgcsdev/smc-error-utils
-
@dgcsdev/smc-logger
-
@dgcsdev/smc-utils
External Dependencies
The influx-writer makes use of a number of common JavaScript framework/library packages that will be installed into the NodeJS environment by the package manager (npm or yarn). The dependencies are illustrated in the structure diagram below. These external dependencies include:-
-
https://www.npmjs.com/package/fs-extra adds file system methods that aren’t included in the native fs module and adds promise support to the fs methods.
-
lodash makes JavaScript easier by taking the hassle out of working with arrays, numbers, objects, strings, etc.
-
https://www.npmjs.com/package/memory-streams is a light-weight implementation of the Stream.Readable and Stream.Writable abstract classes from node.js. You can use the classes provided to store the result of reading and writing streams in memory. This can be useful when you need pipe your test output for later inspection or to stream files from the web into memory without have to use temporary files on disk
-
path is a built-in NodeJS feature for managing files
-
momentjs provides a bunch of functions for manipulating dates and times
-
request-promise-native is a, now deprecated, set of functions used to manage asynchronous web requests (in this case to the influxDB).
JavaScript Structure
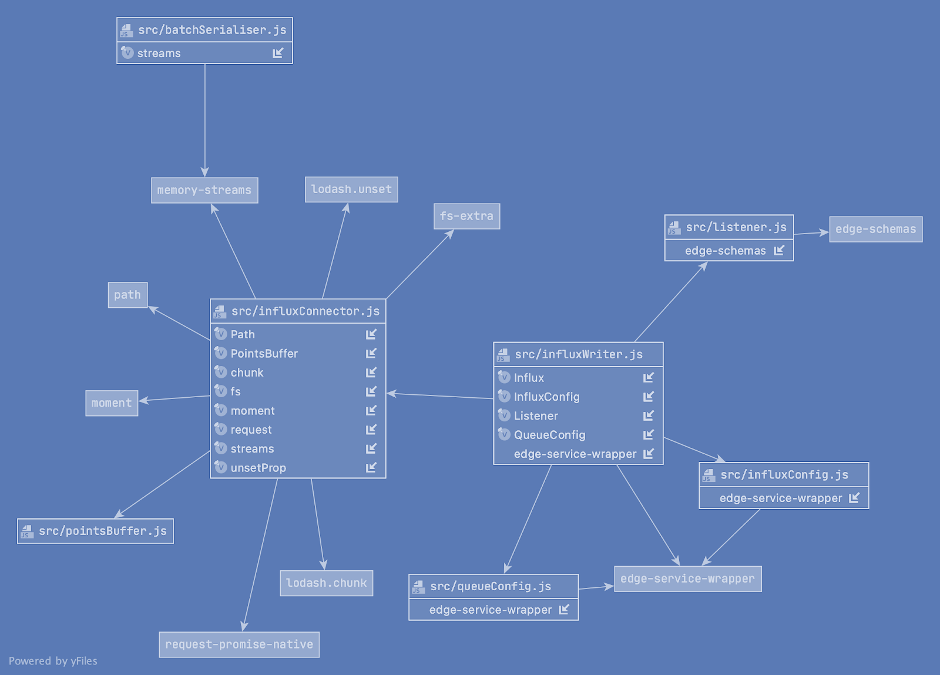
The diagram illustrates the key components of the influx-writer. The modules can be divided into those that support:-
-
Configuration
-
Connection management for MQTT
-
Connection management for Iflux
-
Data buffering
Configuration
influxConfig.js
The i*nflux.js* file uses the Joi schema validation package to assemble and check a series of parameters that are needed to configure an instance of the influx-writer. The parameters are usually set via environment variables which make the mechanism suitable for both local implementations and those hosted in docker.
| Environment Variable | Type | Default | Mandatory | Description |
|---|---|---|---|---|
INFLUX_HOST |
string |
localhost |
No |
Network location of the influx service. This should typically be on localhost' |
INFLUX_PORT |
Number |
8086 |
No |
Influx service api port |
INFLUX_DB |
string |
- |
Yes |
The Influx database name or bucket into which the data will be written |
INFLUX_DB_V2 |
boolean |
false |
No |
Whether the Influx database is version 1.x or version 2.x |
ORGANISATION |
string |
- |
Yes |
The name of the organisation within InfluxDb to which data from this writer will be attached |
INFLUX_API_TOKEN |
string |
- |
No |
The API token created in Influx and used as a Bearer token in the HTTP requests |
queueConfig.js
The queueConfig module evaluates environment variable to set up the key parameters for the buffered writes of data retrieved from the MQTT broker to the Influx DB. The recognised parameter variables are presented in the table below.
| Environment Variable | Type | Default | Mandatory | Description |
|---|---|---|---|---|
WRITE_INTERVAL |
Int (ms) |
5000 |
No |
How frequently are influx writes attempted |
BUFFER_SIZE |
int |
10000 |
No |
Max batch-size for each write. Batching is FIFO |
BUFFER_MAX |
int |
42000 |
No |
Max buffer size. If the buffer hits this limit then the oldest points are discarded |
MAX_RETRIES |
Int >0 |
0 |
No |
Max attempts to write the same batch. 0 implies no limit to number of attempts |
DEAD_LETTER_DIRECTORY |
string |
No |
File Path for storing unwriteable points. If blank, no dead letter store is created |
|
REQUEST_TIMEOUT |
Int (s) |
10 |
No |
Request timeout for batch writes to Influx |
Framework Configuration
A number of environment variables are used by the*_ edge-service-wrapper _*modules that form the dependencies for the influx-writer. These variables tend to control access to key components such as the MQTT broker and the SMTP mail server. All services that incorporate the wrapper as a dependency have their behaviours influenced by the presence, or otherwise, of these environment variables.
| Environment Variable | Type | Default | Mandatory | Description |
|---|---|---|---|---|
SUPPRESS_AGENT_INFO_MESSAGES |
boolean |
false |
No |
The heartbeat.js module implements a regular publication of agent status to the MQTT broker. If set to true this variable disables that heartbeat. |
MQTT_BROKER_DNS_INTERVA |
Int (ms) |
60000 |
No |
If set this variable will cause the framework to poll the DNS entry for the MQTT broker every* <value> *ms. If the MQTT broker has changed it’s address the framework will reconnect to the new address |
MQTT_NO_PUBLISH |
boolean |
false |
No |
If set to true this variable will prevent publishing to MQTT. It would, for example, allow an agent to test with a live broker to subscribe to topics without making its presence known to the live elements of the MicroGrid |
SMC_SEND_ALERTS |
boolean |
true |
No |
By default the framework will mail alerts when it detects a fatal service error (a call to process.on(“…”)). Setting to false will disable this functionality |
SMTP_FROM |
string |
No |
If mail alerts are enabled this variable can be used to set the email address from which the emails originate |
|
MAILGUN_API_KEY |
string |
No |
An API Key to use with Mailgun to authorise the sending of mail messages as alerts |
|
MAILGUN_DOMAIN |
string |
No |
The internet domain name of the Mailgun server to use to send alert e-mails |
|
AGENT_ID |
string |
Yes |
Ensemble ID used to create the topic name that the influx-writer uses to publish its presence to MQTT |
|
AGENT_NAME |
string |
Yes |
Agent name published to other components via MQTT |
|
AGENT_HOST |
string |
No |
The host on which the ensemble lives |
|
AGENT_INFO_MESSAGE_INTERVAL |
int (s) |
60 |
No |
How frequently the ensemble should republish its dynamic details (e.g. uptime) |
MQTT_BROKER_DNS |
string |
No |
The DNS name of the MQTT Broker |
|
MQTT_BROKER_HOST |
string |
No |
The hostname of the machine running the MQTT borker |
|
MQTT_BROKER_PORT |
int |
20200 |
No |
The TCP port number on which the MQTT broker is listening |
MQTT_USEERNAME |
string |
No |
For basic credentials (username and password) the username to supply to the MQTT broker |
|
MQTT_PASSWORD |
string |
No |
A password to supply for authentication with the MQTT broker when basic credentials are in use |
|
MQTT_BROKER_KEEP_ALIVE |
int (s) |
60 |
No |
Keep alive ensures that the connection between the broker and client is still open and that the broker and the client are aware of being connected. When the client establishes a connection to the broker, the client communicates a time interval in seconds to the broker. This interval defines the maximum length of time that the broker and client may not communicate with each other. |
MQTT_BROKER_CLEAN |
boolean |
false |
No |
If set the influx-writer will connect to MQTT using non-persistent (clean) sessions |
MQTT_BROKER_CLIENT_ID |
string |
<ensemble_id>@hostname |
No |
When a client subscribes to a topic, the subscription is associated with the client id and not the connection or username. When a messages is published to a topic, the broker will iterate over all subscriptions matching the topic and look up if any connection is active with the associated client id |
SUPRESS_CONFIG_LISTENER |
boolean |
false |
No |
By default SMC microservices subscribe to configuration topics on MQTT and respond to changes published to them. This flag prevents an agent from doing this |
SUPRESS_HEALTHCHECK |
boolean |
false |
No |
SMC microservices will respond to a healthcheck (see #heading=h.f88eo3uvv1ps[Health Checks]) request. If this variable is set to true the healthcheck behaviour is disabled |
HEALTHCHECK_PORT |
int |
8444 |
No |
The TCP port on which the service listens for a healtcheck request |
NO_MQTT |
boolean |
false |
No |
Indicates that MQTT is unavailable - Test only |
Logical Relationships
The diagram below illustrates the basic structure of the collaborating elements in the influ-writer use case. The writer uses configuration data from the two modules described above to receive notifications from MQTT, reformat the data and write it to the InfluxDB.
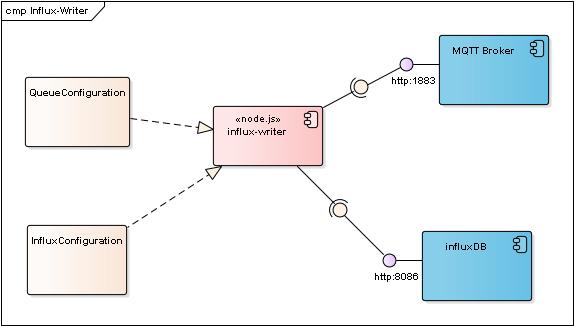
Perhaps the first question then is what data does the influx writer get from MQTT and how does it get it? As we have already discussed, MQTT is a subscribe/publish mechanism so to get any data at all the influx-writer is going to have to subscribe to some topics in MQTT. In addition in order to allow the system to be self-monitoring it will publish to some topics of its own that can be used by other components to monitor the health and status of the writer.
Put simply the influx-writer subscribes to topics that represent signals from devices and publishes its own entry to the devices topics. Note that the influx-writer also subscribes to its own topics.
MQTT Subscriptions
The influx-writer will subscribe to the following topics:-
Topics Related to the influx-writer
devices/{influx writer agent id}/config/ensemble/set
devices/{influx writer agent id}/config/ensemble
devices/{influx writer agent id}/config/influx/set
devices/{influx writer agent id}/config/queue/set
devices/{influx writer agent id}/config/influx
devices/{influx writer agent id}/config/queue
Influx Writer Initialisation
Subscription Setup
Subscription setup happens during the start-up of the influx-writer. A short time sequence diagram below illustrates the steps in setting up the subscriptions. The process follows the following steps:-
-
The Runner which forms part of the @dgscdev packages that we described under DGCSDEV Dependencies is used to initialise the objects and module that are needed to implement the* influx-writer*[1.0].
-
The influxWriter then calls initialise() on both the queueConfig module and the influxConfig module [1.1,1.2].
-
This causes the evaluation and checking of the environment variables described above
-
The Runner will then instantiate the Influx and listener objects by calling their constructors [1.3,1.4]
-
The Runner calls the start() function on the *influxWrite*r [1.5]
-
The influxWriter then hands back control to the Runner calling startAll and passing it the list of now instantiated objects [1.6]
-
The Runner uses the* @dgcsdev-mqtt* module to publish the influx-writer configuration and status topics[1.7,1.8]
-
On the return from startAll() the influxWriter start() function calls the associated start() method on the listener which then is able to subscribe to the MQTT topics for the signal data[1.9,1.10]
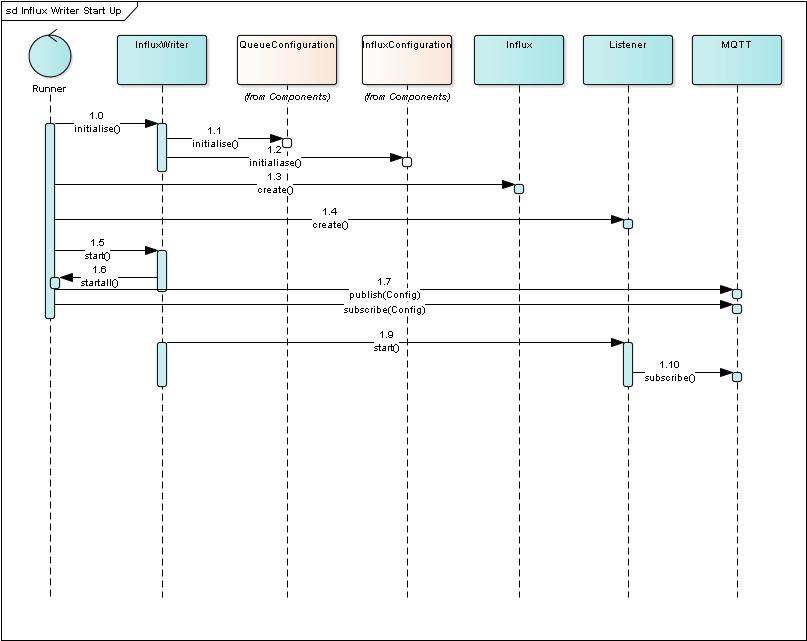
Ensemble config
As mentioned in #heading=h.gqj08eualbwa[DGCSDEV Dependencies] the influx-writer inherits core behaviour from a number of dependent modules. A key core inherited behaviour is from the edge-service-wrapper module (described separately). An important aspect of this inherited behaviour is the ensemble configuration functions.
The influx-writer publishes a description of its configuration elements to the rest of the SMC ecosystem as a JSON payload. For each configuration item it supplies a type, a description, a default value and a unit.
{"time":"2020-10-28T16:11:52.611Z",
"value":{"type":"object",
"fields":{"writeInterval":{
"type":"int",
"description":"How frequently are influx writes attempted",
"default":5000,
"dort":5,
"unit":"ms"},
"batchSize":{
"type":"int",
"description":"Max batch-size for each write. Batching is FIFO",
"default":10000,
"sort":4},
"bufferMax":{
"type":"int",
"description":"Max buffer size. If the buffer hits this limit then the oldest points are discarded",
"default":420000},
"maxRetries":{
"type":"int",
"description":"Max attempts to write the same batch. 0 implies no limit to number of attempts",
"default":0},
"deadLetterDirectory":{
"type":"string",
"description":"Filepath for storing unwriteable points. If blank no dead letter store is created."},
"requestTimeout":{
"type":"int",
"description":"Request timeout for batch writes",
"default":10,
"sort":3,
"unit":"s"}}}}
Edge Schema & DTOs
We described above the MQTT topics which the influx-writer subscribes to. The mechanism used to respond to messages that are published on these topics is to use a set of asynchronous listeners that write to global property storage. The implementation of these listeners is wrapped in the DTO and DAO implementations provided in the @dgcsdev/edge-schemas module that forms a dependency for the influx-writer. The global storage uses simple Set() and Map() object instances to carry key/value pairs. A series of asynchronous subscriptions are set up for each the topics:-
-
devices//signal/
-
devices//signal//nodata
-
devices/+/$online
Subscriptions listen for the events error, stop and data on each topic and attach a call back function or lambda to the event processing. For error and stop events the call back actions are broadly equivalent but the data function is specific to the topic data. For example, the function for the $online topic is mapped to a call back function on the DeviceSubscriber DTO Class which treats the values received on the topic as a tri-state “boolean” , true, false null. The list of subscribers
| Topic | Subscriber | Creates DTO | Contract |
|---|---|---|---|
devices/+/$online |
DeviceSubscriber |
DeviceDto |
boolean |
devices//signal/ |
SignalSubscriber |
SignalDto |
any |
devices//signal//nodata |
NoDataSubscriber |
SignalNoDataDto |
any |
As the subscribers receive MQTT publish messages these are matched to the subscriber class in the table above and instances of the DTOs created and saved in a global properties store associated with the MQTT Broker client object.
Influx Listener Process - The Main Loop
Logical Overview
The main loop of the influx-writer service is essentially very simple. Messages arrive from the MQTT broker, these messages contain signals that have been measured in the EP. They may be voltages, signal strengths, system uptime or whatever has been instrumented by the agents in the EP. As they arrive they are buffered into memory and periodically the buffer is written to the influx Database. This is a common design pattern and would normally be achieved with two synchronised threads, a reader and a writer.
Threads? What Threads?
JavaScript in a nodeJs container follows the same model as it does executing in a browser. It is effectively a single threaded process using cooperative scheduling. Transfer of control from one task to another only happens when the executing code yields control or calls a library function that operates asynchronously - normally some form of I/O operation. This has always been a common model in UI centric code and
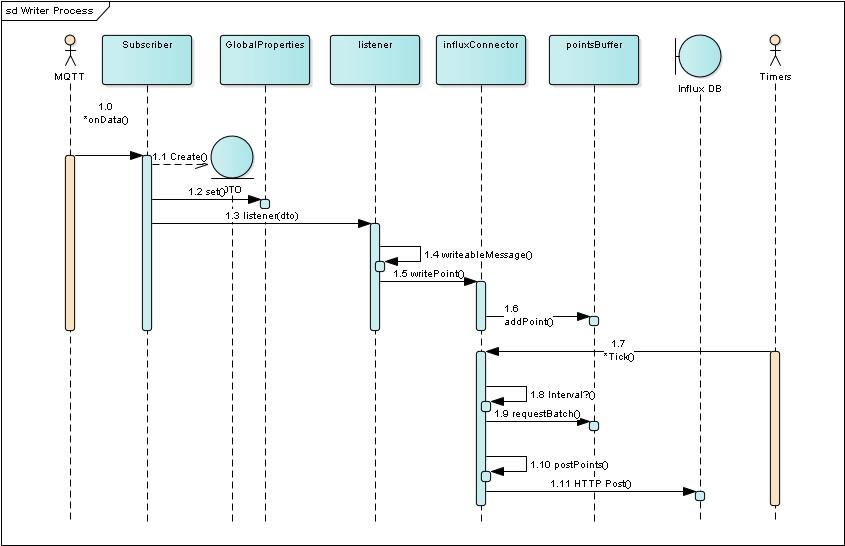
Message Receiver
The sequence diagram above illustrates the logical view of what happens in this main loop, in reality a loop not shown here is scheduling each of the callback functions off LIFO queues that hold the list of event handlers for asynchronous functions and timers.
-
The MQTT client indicates the arrival of a signal message bey calling the onData function of an instance of the Subscriber class [1.0]
-
The Subscriber creates an instance of the DAO objects (see for example GlobalSignalDAO) [1.1]
-
The DTOs are held in the globalProperties cache - simply a Map [1.2]
-
The DTO is passed to the listener [1.3]
-
The listener converts the incoming data from the MQTT message into a JSON object that represents the signal value, name and timestamp. [1.4]
Each point is represented by a JSON object the contains the following fields:-
-
Measurement - a string constructed by concatenating the deviceId that supplied the MQTT signal message along with the signalId separated by a / character
-
Tags a JSON object that comprises two strings , device and field that are used as correlation ids for the data in the database.
-
Value - the signal value
-
Timestamp - a timestamp when the EP agent processed the signal
An example of a typical writable point would be a JSON value:- +
{ +
"measurement": "caederwen_ATS/synth_load_power", +
"tags": { +
"device": "caederwen_ATS", +
"field": "synth_load_power" +
}, +
"value": 3, +
"timestamp": "2020-11-11T14:53:01.258Z" +
}
The writable message is passed to the influxConnector when the listener calls writePoint()[*1.5]. The *influxConnector adds the data point to the pointsBuffer by alling its *addPoint() *function [1.6]
Tick-Tock
An Interval timer is set up with a periodicity that is configured using the WRITE_INTERVAL configuration variable (see #heading=h.slum7oe5qozb[Configuration]). When the timer interval has expired and there are no higher priority callbacks to service the NodeJS main loop will call influxConnector tick() function [1.7]. The function checks that the elapsed time expired is greater than the configured interval[1.8] and then calls the *requestBatch() *function supplied by the points buffer[1.9]
The data points are batched into a block size that is set by the BUFFER_SIZE configuration variable. The influxConnector function postPoints() is then used to create[1.10] a and HTTP request that holds:-
-
The data from the pointsBuffer
-
The URL of the InfluxDB
-
An Authentication token for the database write if InfluxDB version 2.0 is in use or q username and password credential for InfluxDB 1.x
This HTTP Post will write the data to the Influx Datrabase[1.11]
influxConnector Configuration
For test purposes it is possible to configure the influxConnector to read MQTT incoming events, format them but prevent the write to the Influx DB. To achieve this set the NO_UPDATES configuration variable.
| Environment Variable | Type | Default | Mandatory | Description |
|---|---|---|---|---|
NO_UPDATES |
boolean |
false |
No |
Stops the influx-writer from posting data read from the MQTT broker to the influx database |
Service Catalogue
There is only a single accessible service supplied by the influxdb-writer, this is the healthcheck service. An HTTP request to the port set by the HEALTHCHECK_PORT configuration variable will result in the message SERVICE_ALIVE being displayed in the influxdb-writer is running.
Dead Letter Queue
Batches that cannot be written to the InfluxDB - where an error response is received form the HTTP POST request - are written to the Dead Letter Queue if this is configured. The buffer is simply written as a JSON object string to the directory specified in the DEAD_LETTER_DIRECTORY configuration variable.
The JSON Batch will be written to a fil name that is derived from the:-
-
Points buffer index,
-
The number of points that were attempted to be written to Influx
-
The timestamp for the Tick() event that prompted the write