Setting Up Influx V2 Buckets
Influx V1 Compatibility API
Influx V2 stores data in buckets which belong to organisations. It uses different APIs and promotes the use of the FLUX query language over the earlier InfluxQL language. Flux follows a much more functional programming approach whilst InfluxQL aped the SQL style languages used in relational databases. As a consequence Flux offers a richer environment where joins, sorting by tags, data casts etc are better supported than was ever the case in InfluxQL. Flux then is the future target state for queries against our Time Series database and should, therefore, be our direction. The problem that this poses is that ity requires all elements of our ecosystem to be upgraded simultaneously to Flux and this is a not insignificant undertaking. To make this easier Influx V2 provides a backwards compatibility mode that allows old-style InfluxQL queries to be made against V2 buckets. It does not, however, come without the need for some set up and configuration.
Smarter MicroGrid Ecosystem
Our Fargate AWS model now runs with Influx V2 using multiple buckets separated by organisation as detailed here. The InfluxDB Writer processes have been modified to use a native V2 API controlled by the useVersion2 parameter in their deployment object. Other elements, however, have not been updated. In particular the dashboard generators. These still create dashboards with InfluxQL queries. We need, therefore to allow Grafana to access the data via the V1 compatibility mode until we have updated the dashboard generators. This means that the Grafana data source definitions must support V1 queries.
Influx V2 Authorisation
Influx V2 uses a much more sophisticated and fine-grained authorisation model than the simplistic username/password of V1. Each access must be accompanied by a token which defines the detailed access capabilities for that request - which buckets it may read or write, which organisations it may access and so forth. We much prefer this scheme and so it is used by our InfluxDB writers and by our grafana instances.
The influx Command
Not all the configuration we require can be performed through the new Influx DB V2 GUI. For some elements we require access to the influx CLI command. This command is bundled with the docker container but docker exec is at best complicated in a Fargate deployment, so it makes most sense to download the influxV2 OSS bundle and use the influx command supplied with it.
Create a Configuration
Extract the 'root' token from the deployed docker image - the token will be in the influx-configs file on the persistent storage volume that was mapped as /etc/influxdb2. Create a boot configuration with the influx command using the extracted token, the URL for the Influx database and the root organisation that was used when the container was deployed - this is the organisation value in the typescript interface InfluxDBversion2 for the CDK deployment.
./influx config create -n boot -u <influxdb_url:8086> -o <root organisation> -t <token>
# Make the configuration active
./influx config set -a -n bootCreate Organisations & Users
our standard model for InfluxV2 is a single bucket named 'signals' that belongs to an organisation with a single user that manages that bucket. This organisational bucket is then mapped to a v1 database for use as a Grafana data source. Each InfluxDB writer maps signals for an MQTT broker to the 'signals' bucket of its associated organisation. If we have a deployment with two writers from MQTT brokers dgops and caederwen we would write the data to a signals bucket for each organisation. We create a single user to manage the bucket through the Influx V2 GUI.
./influx org create -n dgops
./influx user create -n dgops -p <dgopspassword>
./influx org create -n caederwen
./influx user create -n caederwen -p <caederwenpassword>Create Memberships
Add the dgops and caederwen users to their appropriate organisations. To do this it is necessary to list the users to get their user id and add this as a member of the organisation
./influx user list
./influx org members add -n dgops -m <dgops-user-id>
/influx org members add -n caederwen -m <caederwen-user-id>Create Buckets
Now that the organisations and users exist we can create the buckets
./influx bucket create -d "DGOPS MQTT Signals" -n signals -o dgops
./influx bucket create -d "Caederwen MQTT Signals" -n signals -o caederwenCreate Auth Tokens
Before we can read from or write to the buckets we need to have an auth token. To create the tokens we need both the bucket id and the organisation id which we can get from the list buckets command. Note that the command must be supplied the organisation or it will not list the buckets for that organisation - only the root organisation.
./influx bucket list -o dgops
./influx auth create -d "DGOPS InfluxDB Writer Token" -o dgops -u dgops --write-bucket <bucket id>
# Activate token
./influx auth active --id <auth token id>
./influx bucket list -o caederwen
./influx auth create -d "Caederwen InfluxDB Writer Token" -o caederwen -u caederwen --write-bucket <bucket-id>
# Activate token
./influx auth active --id <auth token id>Mapping To V1
Finally, we map the buckets to 'database names' that can be used in the Grafana data source.
./influx v1 dbrp create --bucket-id <bucket-id> --org-id <org-id> --rp infinite --db dgops
./influx v1 dbrp create --bucket-id <bucket-id> --org-id <org-id> --rp infinite --db caederwenConfiguring the Grafana Datasource
Switch to the associated Grafana organisation - for example 'DGOPS Auto' and on settings choose Data Sources. Create a data source which will be the default database for this organisation. An example is shown below:-
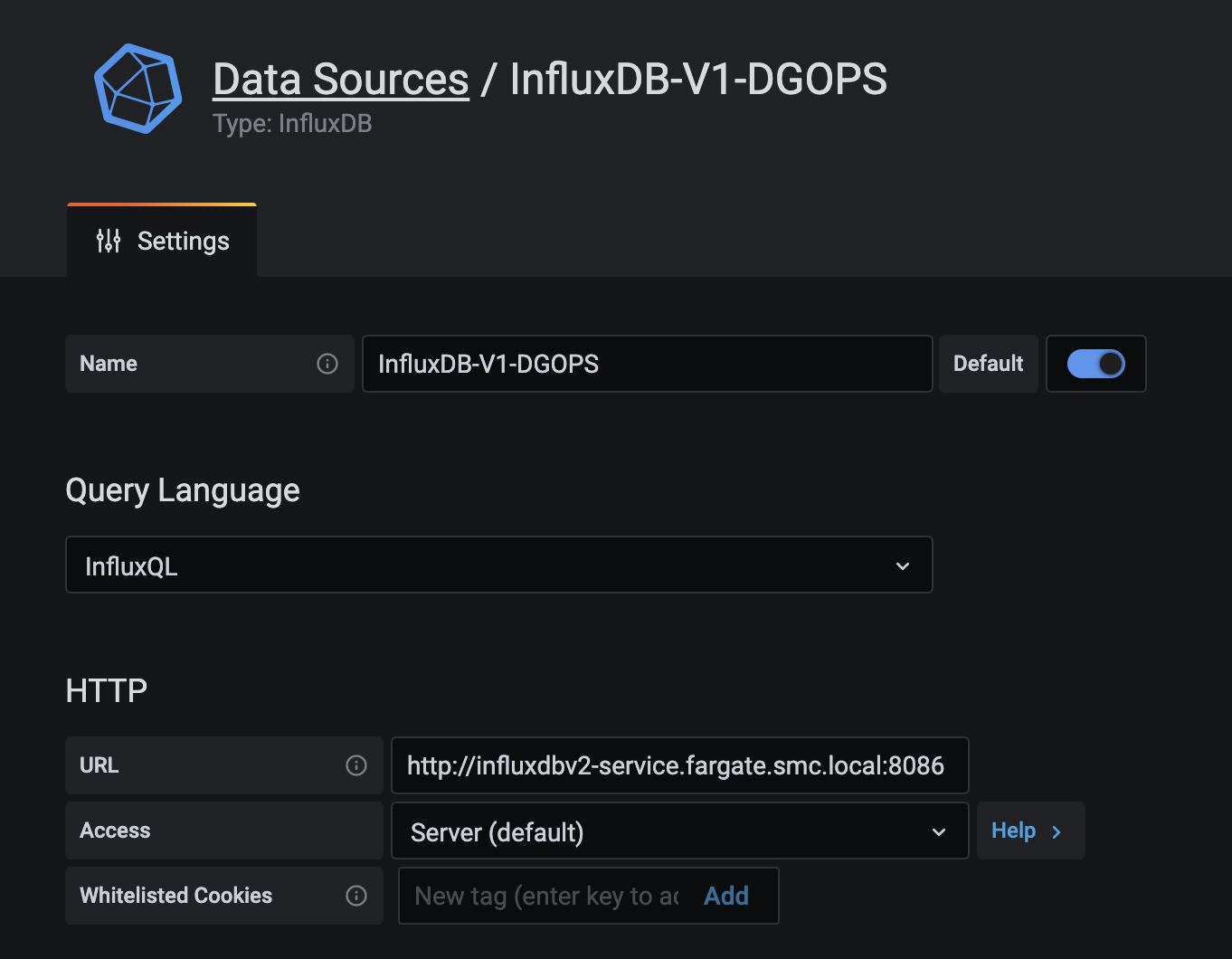
Select InfluxQL as the query language and supply the URL of the V2 Influx DB. Now we can set up the authentication:-
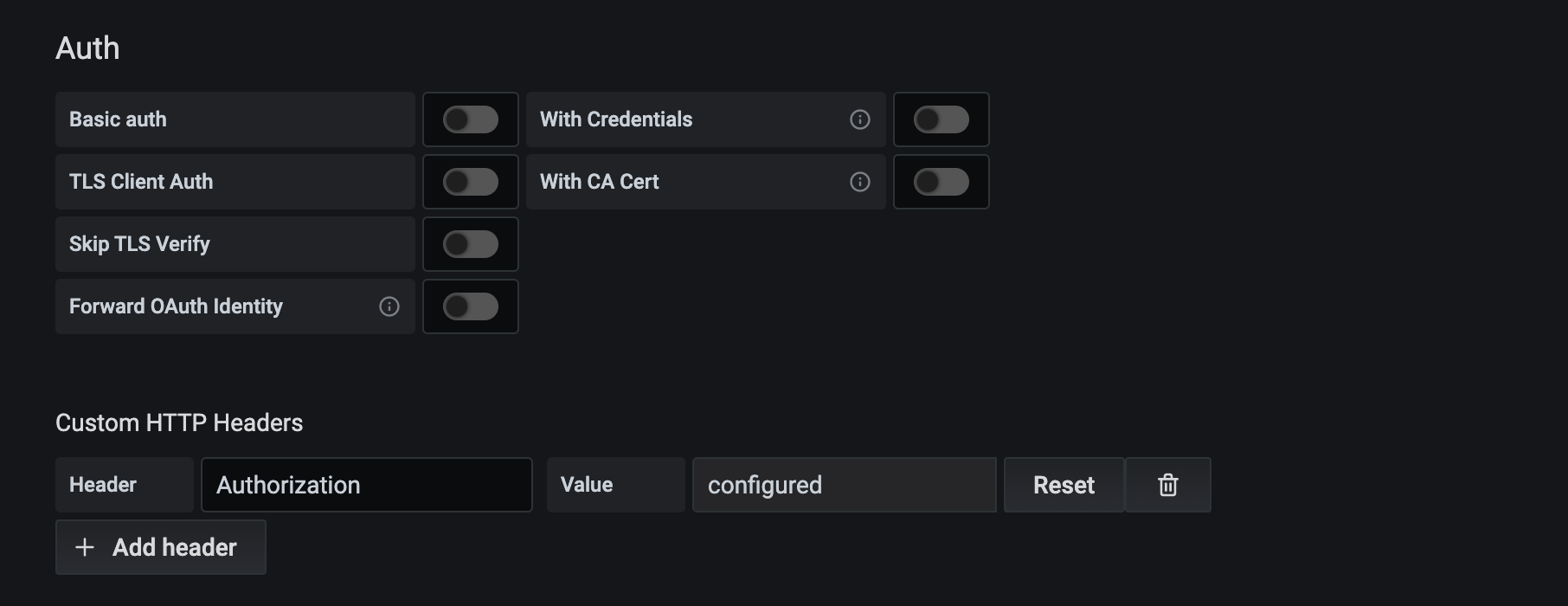
We will use the V2 authentication token so set all the basic Auth switches to "off". Now click the Add Header button to add a custom HTTP header. Set the name of the header to Authorization (note the american spelling). The value for the header should be the word Token followed by a space and then the value of an Influx V2 auth token with at least read access to the bucket that will underpin the Datasource.
Now all that remains is to configure the database reference to the Influx Bucket:-
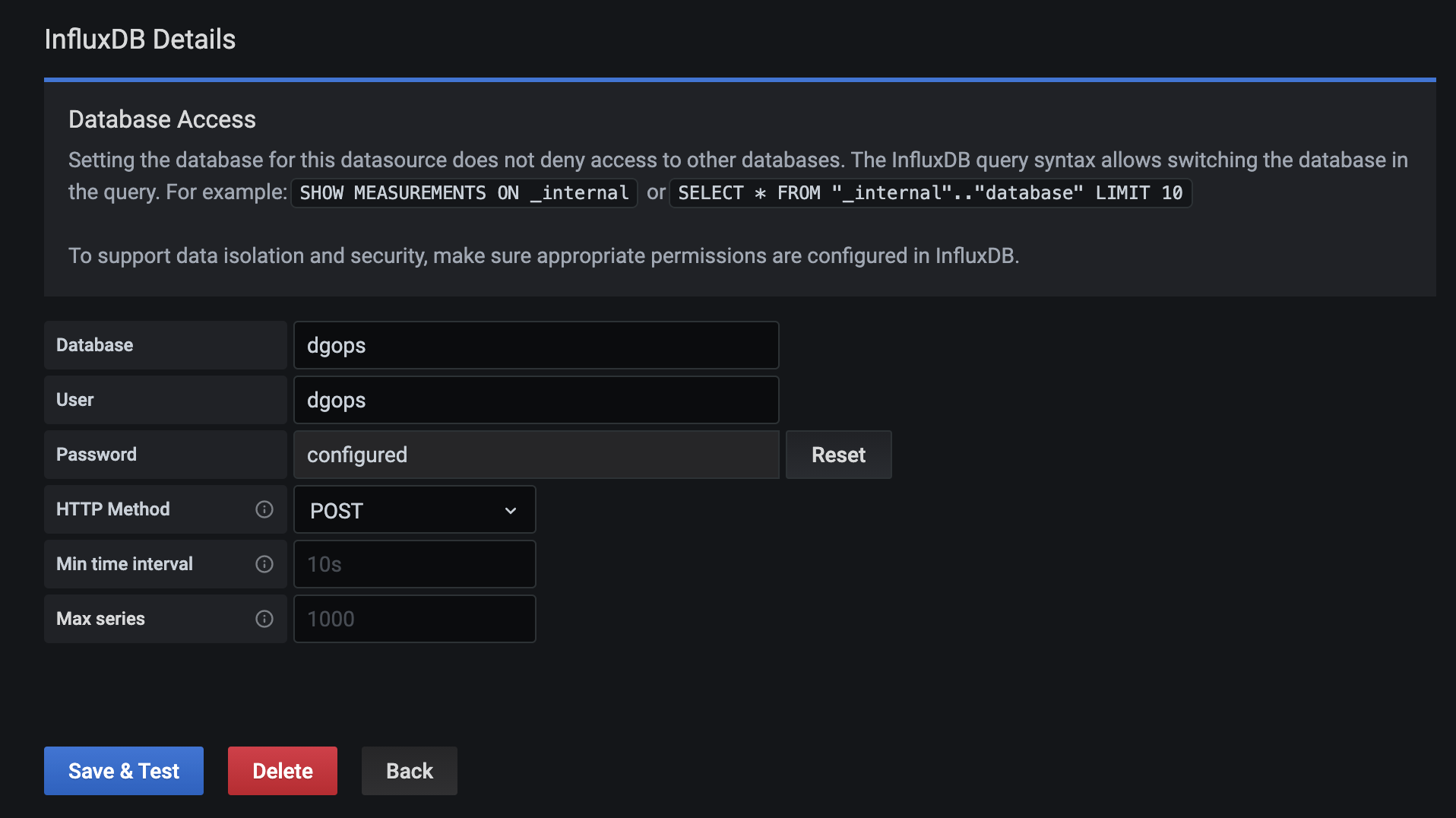
Enter the database name and user associated with the organisation whose signals bucket we wish to access - say for example dgops.
Save and test the data source